Nginx 中的进程间通信
我们知道,Linux 提供了多种进程间传递消息的方式,比如共享内存、套接字、管道、消息队列、信号等,每种方式都各有特点,各有优缺点。其中 Nginx 主要使用了其中的三种方式:
- 套接字(匿名套接字对)
- 共享内存
- 信号
本文主要结合代码讲一下前两种方式,匿名套接字对和共享内存在 Nginx 中的使用。
1. Nginx 中的 channel 通信机制
1.1 概述
首先简单的说一下 Nginx 中 channel 通信的机制。
Nginx中的 channel 通信,本质上是多个进程之间,利用匿名套接字(socketpair)对来进行通信。
我们知道,socketpair 可以创建出一对套接字,在这两个套接字的任何一个上面进行写操作,在另一个套接字上就可以相应的进行读操作,而且这个管道是全双工的。
那么,当父进程在调用了 socketpair 创建出一对匿名套接字对(A1,B1)后,fork 出一个子进程,那么此时子进程也继承了这一对套接字对(A2,B2)。在这个基础上,父子进程即可进行通信了。例如,父进程对 A1 进行写操作,子进程可通过 B2 进行相应的读操作;子进程对 B2 进行写操作,父进程可以通过 A1 来进行相应的读操作等等。
我们假设,父进程依次 fork 了 N 个子进程,在每次 fork 之前,均如前所述调用了 socketpair 建立起一个匿名套接字对,这样,父进程与各个子进程之间即可通过各自的套接字对来进行通信。
但是各子进程之间能否使用匿名套接字对来进行通信呢?
我们假设父进程 A 中,它与子进程 B 之间的匿名套接字对为 AB[2],它与子进程 C 之间的匿名套接字对为 AC[2]。且进程 B 在进程 C 之前被 fork 出来。
对进程 B 而言,当它被 fork 出来后,它就继承了父进程创建的套接字对,这里我们将其命名为 BA[2],这样父进程通过操作 AB[2],子进程 B 通过操作 BA[2],即可实现父子进程 A 和 B 之间的通信。
对进程 C 而言,当它被 fork 出来后,他就继承了父进程穿件的套接字对,这里我们将其命名为 CA[2],这样父进程通过操作 AC[2],子进程 C 通过操作 CA[2],即可实现父子进程 A 和 C 之间的通信。
但 B 和 C 有一点不同。由于 B 进程在 C 之前被 fork,B 进程无法从父进程中继承到父进程与 C 进程之间的匿名套接字对,而 C 进程在后面被 fork 出来,它却从父进程处继承到了父进程与子进程 B 之间的匿名套接字对。
这样,之后被 fork 出来的进程 C,可以通过它从父进程那里继承到的与 B 进程相关联的匿名套接字对来向进程 B 发送消息,但进程 B 却无法向进程 C 发送消息。
当子进程数量比较多时,就会造成这样的情况:即后面的进程拥有前面每一个子进程的匿名套接字,但前面的进程则没有后面任何一个子进程的匿名套接字。
那么这个问题该如何解决呢?这就涉及到进程间传递文件描述符这个话题了。可以参考这里:进程之间传递文件描述符。一个子进程被 fork 出来后,它可以依次向在它之前被 fork 出来的所有子进程传递自己的描述符(匿名套接字对中的一个)。
通过这种机制,子进程之间也可以进行通信了。
Nginx 中也就是这么做的。
1.2 Nginx 中的具体实现
在 ngx_process.c 中,定义了一个全局的数组 ngx_processes:
ngx_process_t ngx_processes[NGX_MAX_PROCESSES];
其中,ngx_process_t 类型定义为:
typedef struct {
ngx_pid_t pid;
int status;
ngx_socket_t channel\[2\];
ngx_spawn_proc_pt proc;
void *data;
char *name;
unsigned respawn:1;
unsigned just_spawn:1;
unsigned detached:1;
unsigned exiting:1;
unsigned exited:1;
} ngx_process_t;
在这里,我们只关心成员 channel 成员,这个两元素的数组即用来存放一个匿名套接字对。
我们假设程序运行后,有 1 个 master 进程和 4 个 worker 进程。那么,对这 5 个进程而言,每个进程都有一个 4 元素的数组 ngx_processes[4],数组中每个元素都是一个 ngx_process_t 类型的结构体,包含了相应的某个 worker 进程的相关信息。我们这里关心的是每个结构体的 channel 数组成员。
绘制成表如下:
上表的每一列表示每个进程的 ngx_processes 数组的各个元素的 channel 成员。
其中,master 进程列中的每一个元素,表示master进程与对应的每个 worker 进程之间的匿名套接字对。
而每一个 worker 进程列中的每一个元素,表示该 worker 进程与对应的每个 worker 进程之间的匿名套接字对。当然这只是一个粗略的说法,与真实情况并不完全相符,还有很多细节需要进一步阐述。
我们直接借助《深入剖析 Nginx》,直接看下图的实例:
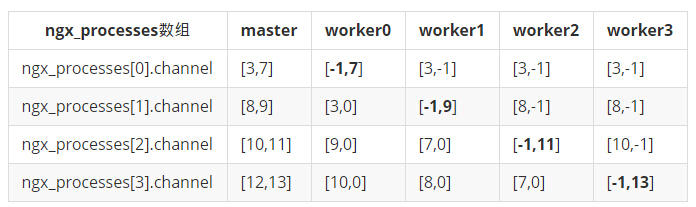
再次感谢《深入剖析 Nginx》的作者高群凯,觉得在这里我没法表达的比他更好了。所以下面会引用很多该书中的内容。
在上表中,每一个单元格的内容分别表示 channel[0] 和 channel[1] 的值,-1表示这之前是描述符,但在之后被主动 close() 掉了,0 表示这一直都无对应的描述符,其他数字表示对应的描述符值。
每一列数据都表示该列所对应进程与其他进程进行通信的描述符,如果当前列所对应进程为父进程,那么它与其它进程进行通信的描述符都为 channel[0] (其实 channel[1] 也可以);如果当前列所对应的进程为子进程,那么它与父进程进行通信的描述符为 channel[1](注:这里书中说的太简略,应该为如果当前列所对应的进程为子进程,那么它与父进程进行通信的描述符为该进程的 ngx_processes 数组中,与本进程对应的元素中的 channel[1],在图中即为标粗的对角线部分,即 [-1,7],[-1,9],[-1,11],[-1,13]这四对),与其它子进程进行通信的描述符都为本进程的 ngx_processes 数组中与该其它进程对应元素的 channel[0]。
比如,[3,7] 单元格表示,如果父进程向 worker0 发送消息,需要使用 channel[0],即描述符 3,实际上 channel[1] 也可以,它的 channel[1] 为 7,没有被 close() 关闭掉,但一直也没有被使用,所以没有影响,不过按道理应该关闭才是。
再比如,[-1,7] 单元格表示如果 worker0 向 master 进程发送消息,需要使用 channel[1],即描述符 7,它的 channel[0] 为 -1,表示已经 close() 关闭掉了(Nginx某些地方调用 close() 时并没有设置对应变量为 -1,这里只是为了更好的说明,将已经 close() 掉的描述符全部标记为 -1)。
越是后生成的 worker 进程,其 ngx_processes 数组的元素中,channel[0] 与父进程对应的 ngx_processes 数组的元素中的 channel[0] 值相同的越多,因为基本都是继承而来,但前面生成的 worker 进程,其 channel[0] 是通过进程间调用 sendmsg 传递获得的,所以与父进程对应的 channel[0] 不一定相等。比如,如果 worker0 向 worker3 发送消息,需要使用worker0 进程的 ngx_processes[3] 元素的 channel[0],即描述符 10,而对应 master 进程的 ngx_processes[3] 元素的 channel[0] 却是 12。虽然它们在各自进程里表现为不同的整型数字,但在内核里表示同一个描述符结构,即不管是 worker0 往描述符 10 写数据,还是master 往描述符 12 写数据,worker3 都能通过描述符 13 正确读取到这些数据,至于 worker3 怎么识别它读到的数据是来自 worker0,还是 master,就得靠其他收到的数据特征,比如pid,来做标记区分。
关于上段讲的,一个子进程如何区分接收到的数据是来自哪一个进程,我们可以看一下 Nginx-1.6.2中的一段代码:
ngx_int_t
ngx_write_channel(ngx_socket_t s, ngx_channel_t *ch, size_t size,
ngx_log_t *log)
{
ssize_t n;
ngx_err_t err;
struct iovec iov[1];
struct msghdr msg;
#if (NGX_HAVE_MSGHDR_MSG_CONTROL)
union {
struct cmsghdr cm;
char space[CMSG_SPACE(sizeof(int))];
} cmsg;
if (ch->fd == -1) {
msg.msg_control = NULL;
msg.msg_controllen = 0;
} else {
msg.msg_control = (caddr_t) &cmsg;
msg.msg_controllen = sizeof(cmsg);
ngx_memzero(&cmsg, sizeof(cmsg));
cmsg.cm.cmsg_len = CMSG_LEN(sizeof(int));
cmsg.cm.cmsg_level = SOL_SOCKET;
cmsg.cm.cmsg_type = SCM_RIGHTS;
/*
* We have to use ngx_memcpy() instead of simple
* *(int *) CMSG_DATA(&cmsg.cm) = ch->fd;
* because some gcc 4.4 with -O2/3/s optimization issues the warning:
* dereferencing type-punned pointer will break strict-aliasing rules
*
* Fortunately, gcc with -O1 compiles this ngx_memcpy()
* in the same simple assignment as in the code above
*/
ngx_memcpy(CMSG_DATA(&cmsg.cm), &ch->fd, sizeof(int));
}
msg.msg_flags = 0;
#else
if (ch->fd == -1) {
msg.msg_accrights = NULL;
msg.msg_accrightslen = 0;
} else {
msg.msg_accrights = (caddr_t) &ch->fd;
msg.msg_accrightslen = sizeof(int);
}
#endif
iov[0].iov_base = (char *) ch;
iov[0].iov_len = size;
msg.msg_name = NULL;
msg.msg_namelen = 0;
msg.msg_iov = iov;
msg.msg_iovlen = 1;
n = sendmsg(s, &msg, 0);
if (n == -1) {
err = ngx_errno;
if (err == NGX_EAGAIN) {
return NGX_AGAIN;
}
ngx_log_error(NGX_LOG_ALERT, log, err, "sendmsg() failed");
return NGX_ERROR;
}
return NGX_OK;
}
在调用时,参数 ch 即为发送的数据部分,其类型定义如下:
typedef struct {
ngx_uint_t command;
ngx_pid_t pid;
ngx_int_t slot;
ngx_fd_t fd;
} ngx_channel_t;
可见,其中就包含了发送方的pid。
最后,就目前 Nginx 代码来看,子进程并没有往父进程发送任何消息,子进程之间也没有相互通信的逻辑。也许是因为 Nginx 有其他一些更好的进程通信方式,比如共享内存等,所以这种 channel 通信目前仅作为父进程往子进程发送消息使用。但由于有这个架构在,可以很轻松使用 channel 机制来完成各进程间的通信任务。
1.3 Nginx 中的相关代码流程
下面,将上面所讲的内容,在 Nginx 代码中的流程,大概梳理一遍。本文所有代码片段,均来自于nginx-1.6.2。
首先是 main 函数调用 ngx_master_process_cycle:
if (ngx_process == NGX_PROCESS_SINGLE) {
ngx_single_process_cycle(cycle);
} else {
ngx_master_process_cycle(cycle);
}
return 0;
ngx_master_process_cycle调用ngx_start_worker_processes`:
ccf = (ngx_core_conf_t *) ngx_get_conf(cycle->conf_ctx, ngx_core_module);
ngx_start_worker_processes(cycle, ccf->worker_processes,
NGX_PROCESS_RESPAWN);
ngx_start_cache_manager_processes(cycle, 0);
在 ngx_start_worker_processes 函数中,完成对所有 worker 进程的 fork 操作:
static void
ngx_start_worker_processes(ngx_cycle_t *cycle, ngx_int_t n, ngx_int_t type)
{
ngx_int_t i;
ngx_channel_t ch;
ngx_log_error(NGX_LOG_NOTICE, cycle->log, 0, "start worker processes");
ngx_memzero(&ch, sizeof(ngx_channel_t));
ch.command = NGX_CMD_OPEN_CHANNEL;
for (i = 0; i < n; i++) {
ngx_spawn_process(cycle, ngx_worker_process_cycle,
(void *) (intptr_t) i, "worker process", type);
ch.pid = ngx_processes[ngx_process_slot].pid;
ch.slot = ngx_process_slot;
ch.fd = ngx_processes[ngx_process_slot].channel[0];
ngx_pass_open_channel(cycle, &ch);
}
}
上述代码调用的 ngx_spawn_process 即完成具体的 socketpair() 操作和 fork 操作:
ngx_pid_t
ngx_spawn_process(ngx_cycle_t *cycle, ngx_spawn_proc_pt proc, void *data,
char *name, ngx_int_t respawn)
{
......
if (socketpair(AF_UNIX, SOCK_STREAM, 0, ngx_processes[s].channel) == -1)
{
ngx_log_error(NGX_LOG_ALERT, cycle->log, ngx_errno,
"socketpair() failed while spawning \"%s\"", name);
return NGX_INVALID_PID;
}
......
ngx_channel = ngx_processes[s].channel[1];
......
ngx_process_slot = s;
pid = fork();
......
}
在上一段代码中可以看到,master 进程在调用 socketpair 后,将生成的 channel[1] 保存在全局变量 ngx_channel 中,ngx_channel 全局变量的作用是,子进程中会使用该全局变量,并加入到自己的事件集中,达到的效果即是子进程将 channel[1] 加入到自己的事件集中。
话分两头,我们先来具体看看子进程的流程。
在主进程执行完 fork 之后,ngx_start_worker_processes 会调用 proc 回调:
pid = fork();
switch (pid) {
case -1:
ngx_log_error(NGX_LOG_ALERT, cycle->log, ngx_errno,
"fork() failed while spawning \"%s\"", name);
ngx_close_channel(ngx_processes[s].channel, cycle->log);
return NGX_INVALID_PID;
case 0:
ngx_pid = ngx_getpid();
proc(cycle, data);
break;
default:
break;
}
其中,proc 即为 ngx_worker_process_cycle。ngx_worker_process_cycle 会调用ngx_worker_process_init 函数,子进程将从父进程处继承到的 channel[1] 加入到自己的事件集中,就是在这个函数中完成的:
static void
ngx_worker_process_init(ngx_cycle_t *cycle, ngx_int_t worker)
{
......
for (n = 0; n < ngx_last_process; n++) {
if (ngx_processes[n].pid == -1) {
continue;
}
if (n == ngx_process_slot) {
continue;
}
if (ngx_processes[n].channel[1] == -1) {
continue;
}
if (close(ngx_processes[n].channel[1]) == -1) {
ngx_log_error(NGX_LOG_ALERT, cycle->log, ngx_errno,
"close() channel failed");
}
}
if (close(ngx_processes[ngx_process_slot].channel[0]) == -1) {
ngx_log_error(NGX_LOG_ALERT, cycle->log, ngx_errno,
"close() channel failed");
}
#if 0
ngx_last_process = 0;
#endif
if (ngx_add_channel_event(cycle, ngx_channel, NGX_READ_EVENT,
ngx_channel_handler)
== NGX_ERROR)
{
/* fatal */
exit(2);
}
......
}
具体的将 channel[1] 添加到事件集中的操作,是由 ngx_add_channel_event 来完成的,对应的回调处理函数为 ngx_channel_handler,同时我们看到,在添加之前,还进行了很多 close 的工作,这就于之前的示例表里,那些描述符为 -1 的表项相对应了。
此时,子进程已经将从父进程那里继承来的 channel[1] 加入到了自己的监听事件集中,这样,一个子进程从自己的 ngx_processses 数组中,对应本进程的那一个元素中的 channel[1] 中,即可读取来自其他进程的消息。收到消息时,将执行设置好的回调函数ngx_channel_handler,把接收到的新子进程的相关信息存储在自己的全局变量ngx_processes 数组内。见下面的代码:
static void
ngx_channel_handler(ngx_event_t *ev)
{
......
case NGX_CMD_OPEN_CHANNEL:
ngx_log_debug3(NGX_LOG_DEBUG_CORE, ev->log, 0,
"get channel s:%i pid:%P fd:%d",
ch.slot, ch.pid, ch.fd);
ngx_processes[ch.slot].pid = ch.pid;
ngx_processes[ch.slot].channel[0] = ch.fd;
break;
......
}
我们再回到父进程中。
父进程在从 ngx_spawn_process 返回后,回来继续执行 ngx_start_worker_processes:
static void
ngx_start_worker_processes(ngx_cycle_t *cycle, ngx_int_t n, ngx_int_t type)
{
ngx_int_t i;
ngx_channel_t ch;
ngx_log_error(NGX_LOG_NOTICE, cycle->log, 0, "start worker processes");
ngx_memzero(&ch, sizeof(ngx_channel_t));
ch.command = NGX_CMD_OPEN_CHANNEL;
for (i = 0; i < n; i++) {
ngx_spawn_process(cycle, ngx_worker_process_cycle,
(void *) (intptr_t) i, "worker process", type);
ch.pid = ngx_processes[ngx_process_slot].pid;
ch.slot = ngx_process_slot;
ch.fd = ngx_processes[ngx_process_slot].channel[0];
ngx_pass_open_channel(cycle, &ch);
}
}
其中的 for 循环即表示,父进程会把刚刚生成的子进程的 channel[0],放在一条消息的内容中发送给之前生成的子进程。消息的格式定义为:
typedef struct {
ngx_uint_t command;
ngx_pid_t pid;
ngx_int_t slot;
ngx_fd_t fd;
} ngx_channel_t;
我们看下 ngx_pass_open_channel 函数:
static void
ngx_pass_open_channel(ngx_cycle_t *cycle, ngx_channel_t *ch)
{
ngx_int_t i;
for (i = 0; i < ngx_last_process; i++) {
if (i == ngx_process_slot
|| ngx_processes[i].pid == -1
|| ngx_processes[i].channel[0] == -1)
{
continue;
}
ngx_log_debug6(NGX_LOG_DEBUG_CORE, cycle->log, 0,
"pass channel s:%d pid:%P fd:%d to s:%i pid:%P fd:%d",
ch->slot, ch->pid, ch->fd,
i, ngx_processes[i].pid,
ngx_processes[i].channel[0]);
/* TODO: NGX_AGAIN */
ngx_write_channel(ngx_processes[i].channel[0],
ch, sizeof(ngx_channel_t), cycle->log);
}
}
从该函数定义中,可以很清晰的看到“往之前生成的每个进程发送消息”。对之前的每个子进程,具体消息发送工作,是由函数 ngx_write_channel 完成的。
ngx_write_channel 函数的第一个参数是之前某个进程从 master 进程继承来的 channel[0],第二个参数是发送的内容。其中包含了当前进程的 pid、slot号、command 等信息,最重要的是,包含了当前子进程的 channel[0],其实是实现了一个简单的协议。注意,当前子进程的 channel[0] 虽然存在 ngx_channel_t 类型的消息体中,但真正文件描述符的传递操作,是 ngx_write_channel 通过发送控制信息来完成的。接收进程虽然在接收到的消息体中获得了发送进程的 channel[0] 这个值,但并不能直接使用,必须根据控制信息来获取一个新的文件描述符。参看进程间传递文件描述符。
至此,父子进程间的配合,使得所有的子进程均拥有了其他子进程的 channel[0],而另一方面,由于所有子进程的 channel[1] 已加入到自己的监听事件集,所以子进程之间的通信通道即被建立起来。
值得一提的是,父进程在调用 socketpair() 产生一个匿名套接字对后,再 fork 出一个子进程,那么现在有 4 个文件描述符了。其实对这 4 个文件描述符中的任何一个进行写入,从其他3个描述符中的任何一个均可以进行读取操作。
但 Nginx 通过一些 close() 操作,有意达到这样一种目的:
- 对任何一个子进程,其
ngx_processes数组中,对应其它进程的元素,其channel[0]用来向“该其他进程”发送消息。 - 对任何一个子进程,其
ngx_processes数组中,对应本进程的元素,其channel[1]用来接收来自其他进程的消息,这个其他进程既包括其他子进程,也包括 master 进程。至于如何区分是来自哪个进程,以及该消息是用来做什么的,则通过判断 ngx_channel_t 类型的消息的comman、pid、slot等成员来协商。 - 对 master 进程,其
ngx_processes数组的中,对应相应子进程的元素的channel[0],用来向该子进程发送消息。注:其实channel[1]也可以,但按常理,master 进程的ngx_processes数组所有元素的channel[1]应该关闭的。
2. Nginx 中的共享内存
2.1 概述
共享内存是 Linux 下提供的最基本的进程间通信方法,它通过 mmap 或者 shmget 系统调用在内存中创建了一块连续的线性地址空间,而通过 munmap 或者 shmdt 系统调用可以释放这块内存。使用共享内存的好处是当多个进程使用同一块共享内存时,在任何一个进程修改了共享内存中的内容后,其他进程通过访问这段共享内存都能够得到修改后的内容。
陶辉《深入理解Nginx》
共享内存可以说是最有用的进程间通信方式,也是最快的 IPC 形式。两个不同进程 A、B 共享内存的意思是,同一块物理内存被映射到进程 A、B 各自的进程地址空间。进程 A 可以即时看到进程 B 对共享内存中数据的更新,反之亦然。由于多个进程共享同一块内存区域,必然需要某种同步机制,互斥锁和信号量都可以。
采用共享内存通信的一个显而易见的好处是效率高,因为进程可以直接读写内存,而不需要任何数据的拷贝。对于像管道和消息队列等通信方式,则需要在内核和用户空间进行四次的数据拷贝,而共享内存则只拷贝两次数据:一次从输入文件到共享内存区,另一次从共享内存区到输出文件。实际上,进程之间在共享内存时,并不总是读写少量数据后就解除映射,有新的通信时,再重新建立共享内存区域。而是保持共享区域,直到通信完毕为止,这样,数据内容一直保存在共享内存中,并没有写回文件。共享内存中的内容往往是在解除映射时才写回文件的。因此,采用共享内存的通信方式效率是非常高的。
Linux 中,共享内存可以通过两个系统系统调用来获得,mmap 和shmget,分别属于不同的标准,这不在本文的关注范围之内。mmap 语义上比 shmget 更通用,因为它最一般的做法,是将一个打开的实体文件,映射到一段连续的内存中,各个进程可以根据各自的权限对该段内存进行相应的读写操作,其他进程则可以看到其他进程写入的结果。而 shmget 在语义上相当于是匿名的 mmap,即不关注实体文件,直接在内存中开辟这块共享区域,mmap 通过设置调用时的参数,也可达到这种效果,一种方法是映射 /dev/zero 设备,另一种是使用 MAP_ANON选 项。至于 mmap 和 shmget 的效率,跟不同的内核实现相关,不在本文关注范围内。
除了上面的简单描述外,本文不打算仔细介绍 mmap 和 shmget 的使用。有如下相关资料可以参考:
- Linux环境进程间通信(五): 共享内存(上)
- Linux环境进程间通信(五): 共享内存(下)
- APUE,14.8,15.9
2.2 Nginx 中的实现
那么,在 Nginx 中,到底是选用 mmap 映射到 /dev/null,还是使用 MAP_ANON 选项调用mmap,或者是使用 shmget 呢?看相关实现的代码就会一目了然:
/*
* Copyright (C) Igor Sysoev
* Copyright (C) Nginx, Inc.
*/
#include <ngx_config.h>
#include <ngx_core.h>
#if (NGX_HAVE_MAP_ANON)
ngx_int_t
ngx_shm_alloc(ngx_shm_t *shm)
{
shm->addr = (u_char *) mmap(NULL, shm->size,
PROT_READ|PROT_WRITE,
MAP_ANON|MAP_SHARED, -1, 0);
if (shm->addr == MAP_FAILED) {
ngx_log_error(NGX_LOG_ALERT, shm->log, ngx_errno,
"mmap(MAP_ANON|MAP_SHARED, %uz) failed", shm->size);
return NGX_ERROR;
}
return NGX_OK;
}
void
ngx_shm_free(ngx_shm_t *shm)
{
if (munmap((void *) shm->addr, shm->size) == -1) {
ngx_log_error(NGX_LOG_ALERT, shm->log, ngx_errno,
"munmap(%p, %uz) failed", shm->addr, shm->size);
}
}
#elif (NGX_HAVE_MAP_DEVZERO)
ngx_int_t
ngx_shm_alloc(ngx_shm_t *shm)
{
ngx_fd_t fd;
fd = open("/dev/zero", O_RDWR);
if (fd == -1) {
ngx_log_error(NGX_LOG_ALERT, shm->log, ngx_errno,
"open(\"/dev/zero\") failed");
return NGX_ERROR;
}
shm->addr = (u_char *) mmap(NULL, shm->size, PROT_READ|PROT_WRITE,
MAP_SHARED, fd, 0);
if (shm->addr == MAP_FAILED) {
ngx_log_error(NGX_LOG_ALERT, shm->log, ngx_errno,
"mmap(/dev/zero, MAP_SHARED, %uz) failed", shm->size);
}
if (close(fd) == -1) {
ngx_log_error(NGX_LOG_ALERT, shm->log, ngx_errno,
"close(\"/dev/zero\") failed");
}
return (shm->addr == MAP_FAILED) ? NGX_ERROR : NGX_OK;
}
void
ngx_shm_free(ngx_shm_t *shm)
{
if (munmap((void *) shm->addr, shm->size) == -1) {
ngx_log_error(NGX_LOG_ALERT, shm->log, ngx_errno,
"munmap(%p, %uz) failed", shm->addr, shm->size);
}
}
#elif (NGX_HAVE_SYSVSHM)
#include <sys/ipc.h>
#include <sys/shm.h>
ngx_int_t
ngx_shm_alloc(ngx_shm_t *shm)
{
int id;
id = shmget(IPC_PRIVATE, shm->size, (SHM_R|SHM_W|IPC_CREAT));
if (id == -1) {
ngx_log_error(NGX_LOG_ALERT, shm->log, ngx_errno,
"shmget(%uz) failed", shm->size);
return NGX_ERROR;
}
ngx_log_debug1(NGX_LOG_DEBUG_CORE, shm->log, 0, "shmget id: %d", id);
shm->addr = shmat(id, NULL, 0);
if (shm->addr == (void *) -1) {
ngx_log_error(NGX_LOG_ALERT, shm->log, ngx_errno, "shmat() failed");
}
if (shmctl(id, IPC_RMID, NULL) == -1) {
ngx_log_error(NGX_LOG_ALERT, shm->log, ngx_errno,
"shmctl(IPC_RMID) failed");
}
return (shm->addr == (void *) -1) ? NGX_ERROR : NGX_OK;
}
void
ngx_shm_free(ngx_shm_t *shm)
{
if (shmdt(shm->addr) == -1) {
ngx_log_error(NGX_LOG_ALERT, shm->log, ngx_errno,
"shmdt(%p) failed", shm->addr);
}
}
#endif
上面的代码即是 Nginx 源代码中的 src/os/unix/ngx_shemem.c 的全部内容。可见,整个文件只是为了提供两个接口:ngx_shm_alloc 和ngx_shm_free。而这两个接口的实现,按如下逻辑来决定:
- 如果当前系统的 mmap 系统调用支持 MAP_ANON 选项,则使用带 MAP_ANON 选项的mmap。
- 如果 1 不满足,则如果当前系统 mmap 系统调用支持映射 /dev/zero 设备,则使用 mmap 映射 /dev/zero 的方式来实现。
- 如果上面 1 和 2 都不满足,且如果当前系统支持 shmget 系统调用的话,则使用该系统调用来实现。
看到这里,也许大家就有疑问了,如果当前 3 个条件都不满足怎么办,那就没辙了,ngx_shm_alloc 接口没有相应的定义,只能在链接的时候就不成功了。
另外,关于上面三种情况的判断,都是通过相应的宏是否定义来进行的,而相应的宏的定义,是在auto/unix 脚本中进行的,该脚本会写一端测试程序来判断相应的系统调用是否支持,如果支持,则在 configure 后自动生成的 objs/ngx_auto_config.h 文件中定义对应的宏。
3. channel 机制和共享内存在 Nginx 中的使用情况
前面讲 Nginx 中的 channel 机制时提到,Nginx 虽然提供了这种机制,但目前很少用到,而共享内存却相对用的比较多了。例如,为了统计 Nginx 总体的 http 请求处理情况,需要跨越多个 worker 来计算,Nginx 自带的 http 模块 ngx_http_stub_status_module 即主要依赖共享内存的方式。